機械学習で競馬の回収率100%超えを達成した話
この記事はQiitaに投稿された記事をちょこちょこ改変しながら再投稿したものです。
(https://qiita.com/Mshimia/items/6c54d82b3792925b8199)
今公開しているものは、ここからかなり色々と変更していますが、基本的な考え方は変わっていないので、競馬AIを作ってみたいという方の参考になれば嬉しいです。
はじめに
みなさん競馬はお好きでしょうか? 私は今年から始めた初心者なのですが、様々な情報をかき集めて予想して当てるのは本当に楽しいですね!
最初は予想するだけで楽しかったのですが、『負けたくない』という欲が溢れ出てきてしましました。
そこで、なんか勝てる美味しい方法はないかな〜とネットサーフィンしていたところ、機械学習を用いた競馬予想というのが面白そうだったので、勉強がてら挑戦してみることにしました。
目標
競馬の還元率は70~80%程度らしいので、適当に買っていれば回収率もこのへんに収束しそうです。
なのでとりあえず、出走前に得られるデータを使って、回収率100パーセント以上を目指したいと思います!
設定を決める
一概に競馬予測するといっても、単純に順位を予測するのか、はたまたオッズを考えて賭け方を最適化するのかなど色々とあると思います。また、買う馬券もいろいろな種類があります。
今回は競馬の順位を、3着以内・中位・下位の3グループに分けて、多クラス分類を行う方針でいきたいと思います。
そして予想結果で1位になった馬の単勝式の馬券を買うことにします。理由としては、単勝式の還元率は三連単などの高額馬券が出やすいものなどと比べると高めに設定されているからです。(参考:ブエナの競馬ブログ〜馬券で負けないための知識)
また、人気やオッズの情報は特徴量に使わないで行こうと思います。 人気やオッズを特徴量に入れると、おそらくそちらに引っ張られAIの予想として面白くない結果になると思ったからです。
今回は東京競馬場でのレースにしぼって以下進めていきたいと思います。 なお競馬場を絞る理由ですが、アルゴリズムが貧弱なのとtime.sleepを1秒いれていることにより、レースデータのスクレイピングに時間がかかるためです。(2008~2019のデータを集めるのに50時間ぐらいかかりました...)
面倒ですが、時間さえかければ全ての競馬場についてデータを集められます。
手順
- レースデータをこちらのサイト(netkeiba.com)からスクレイピングして集める。
- データの前処理を行う。
- LightGBM で学習を行いモデルを作成する。
- 作成したモデルを使って、1年間の回収率がどうなっているかを確認する。
スクレイピング
こちらのサイト(netkeiba.com)からスクレイピングして集める。 スクレイピングを行うに当たってrobots.txt(そもそもなかった)や利用規約を読んだ限りでは、大丈夫そうだったので負荷のかけすぎに注意を払いながら行いました。 スクレイピングの方法については以下の記事を参考にさせていただきました。
データを集めた結果はこんなかんじです。

スクレイピングをする際に、過去3レースの成績がない馬については情報を削除しています。 過去の情報がないものに対しては、未来を予測することはできないと考えるからです。
また、地方や海外で走った馬についてはタイム指数などが欠けている場合がありますが、その部分は平均値で埋めています。
特徴量
今回、特徴量として扱ったのは以下の項目です。 開催場所に関しては、今回は東京競馬場のデータのみしか扱わないことから、特徴量からは省いています。 当日のデータ
| 変数名 | 内容 |
|---|---|
| month | 何月開催か |
| kai | 第何回目か |
| day | 開催何日目か |
| race_num | 何Rか |
| field | 芝orダート |
| dist | 距離 |
| turn | どっち回りか |
| weather | 天気 |
| field_cond | 馬場状態 |
| sum_num | 何頭立てか |
| prize | 優勝賞金 |
| horse_num | 馬番 |
| sex | 性別 |
| age | 年齢 |
| weight_carry | 斤量 |
| horse_weight | 馬体重 |
| weight_change | 馬体重の変化量 |
| l_days | 前走から何日経過したか |
過去3レースのデータ(01→前走、02→2レース前、03→3レース前)
| 変数名 | 内容 |
|---|---|
| p_place | 開催場所 |
| p_weather | 天気 |
| p_race_num | 何Rか |
| p_sum_num | 何頭立てか |
| p_horse_num | 馬番 |
| p_rank | 順位 |
| p_field | 芝orダート |
| p_dist | 距離 |
| p_condi | 馬場状態 |
| p_condi_num | 馬場指数 |
| p_time_num | タイム指数 |
| p_last3F | 上がり3ハロンのタイム |
前処理
タイムを秒数表記にしたり、カテゴリ変数をラベルエンコードしただけです。 以下は例として天気をラベルエンコードするコードです。
num = df1.columns.get_loc('weather')
for i in range(df1['weather'].size):
copy = df1.iat[i, num]
if copy == '晴':
copy = '6'
elif copy == '雨':
copy = '1'
elif copy == '小雨':
copy = '2'
elif copy == '小雪':
copy = '3'
elif copy == '曇':
copy = '4'
elif copy == '雪':
copy = '5'
else:
copy = '0'
df1.iat[i, num] = int(copy)
df1['weather'] = df1['weather'].astype('int64')
このように各カテゴリ変数をラベルエンコードしていきます。
LabelEncoderを使えばもっと簡単にできますが、今回は複数のデータファイル間で、変換される数字と変数との互換を統一する必要があったので使いませんでした。
また、今回用いる機械学習フレームワークのLightGBMは弱識別器に決定木を用いているらしいので、標準化をする必要をせずとも学習は可能です。(参考:LightGBM 徹底入門)
ただし、特徴量によってはレース単位で標準化する方が精度が上がる可能性はあります。
予測モデル
勾配ブースティングのフレームワークであるLightGBMでモデルを作ります。これを選んだ理由は、高速かつ非deepでは一番強い(らしい)からです。
そして予測方法ですが、今回は3着以内、3着以内を除く中間1/3、下位1/3という3つのグループのどれかに分類する、多クラス分類にしました。例えば15頭立ての場合、1~3着がグループ0、4~8着がグループ1、9~15着がグループ2となります。
使い方は以下のサイトを参考にさせていただきました。 (参考:【初心者向け】LightGBM (多クラス分類編)【Python】【機械学習】)
学習用データと検証用データは以下のようにします。
| 学習用データ・検証用データ | テストデータ |
|---|---|
| Tokyo_2008_2018 | Tokyo_2019 |
学習用データをtrain_test_splitにて訓練用データとモデル評価データに分割します。
パラメータのチューニングは特におこなっていません。
train_set, test_set = train_test_split(keiba_data, test_size=0.2, random_state=0)
#訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割
X_train = train_set.drop('rank', axis=1)
y_train = train_set['rank']
#モデル評価用データを説明変数データ(X_test)と目的変数データ(y_test)に分割
X_test = test_set.drop('rank', axis=1)
y_test = test_set['rank']
# 学習に使用するデータを設定
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'multiclassova',
'num_class': 3,
'metric': {'multi_error'},
}
model = lgb.train(params,
train_set=lgb_train, # トレーニングデータの指定
valid_sets=lgb_eval, # 検証データの指定
verbose_eval=10
)
動かしてみる
実際に動かしてみました。

正答率は約54%ということになりました。半分以上は当てているということですね。 パラメータをいじってもあまりこの数値は変わらなかったので、今回はこのままいきます。
検証
2019年の1年間、東京競馬場で検証したデータを載せていきます。
ここで、条件として
- 1レースにつき100円で単勝を買う。(当り = オッズ × 100 - 100 or 外れ = -100 )
- 1レース中にデータが残っている馬数が出走頭数の半分以下の場合は買わない。(±0)
としています。 2つ目の条件がある理由ですが、これは2歳戦のような過去のレースデータが3戦以上ある馬が1頭だけといったレースを除外するためです。
以下が結果のグラフです。
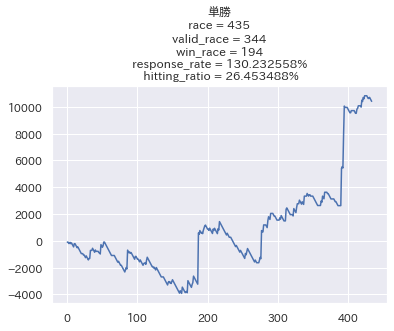
😊良い感じじゃん😊
正直こんなに簡単に回収率が100%を超えるとは思いませんでした。
的中率も26%程度とボチボチ当ててくれています。
2つ目の条件により、100レースほど賭けないレースがでてしまいましたが、およそ8割のレースに参加してこの回収率なら文句なしではないでしょうか?
せっかくなので他の馬券でも検証してみたいと思います。
なお3連単だけは3頭BOX買い(6通り)をする前提で行っています。

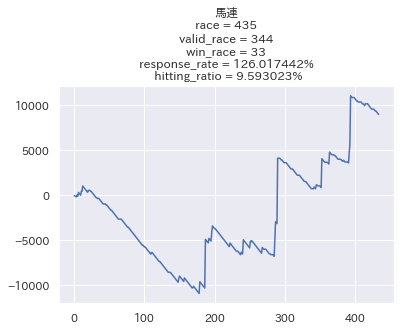
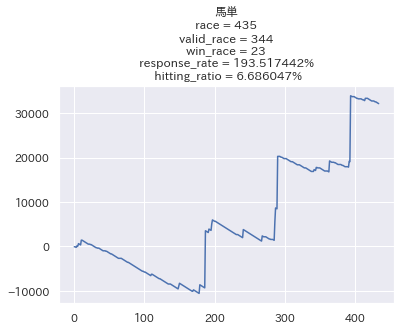
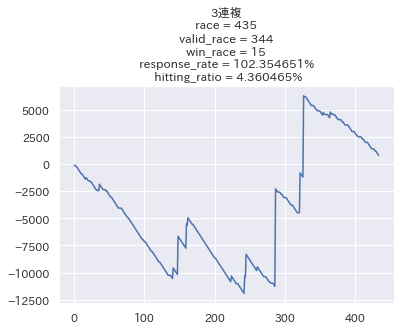
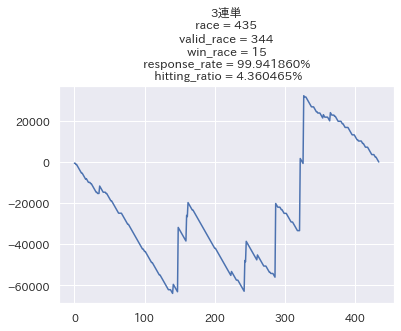
結構良いですね...!馬単に関しては回収率200%近くと素晴らしい結果になっています。 ただ的中率が低い代わりにリターンが大きい馬券は、回収率のブレが大きくなるので参考程度に留めておきたいと思います。
不満点としては、3位以内に入るかどうかで評価しているにも関わらず、複勝の回収率が100%を切っている点ですかね。 この辺をどうにかしていきたいと思います。
さらに条件を付け加えてみる
今のところ馬券を買う条件は頭数のみでしたが、実用的な使い方では全レース買うというよりかは、予想数値の良し悪しで決めることになると思います。
そこで新たに次の条件を付け加えてみたいと思います。
・グループ0に分類される予測数値1位と2位の差が0.1以上の場合のみ買う。
つまりこういう場合のみ買い
 こういう時は買わない
こういう時は買わない
 ということです。
ということです。
この条件にする理由は 1. 3位以内に入るかどうかの予測数値は、強い馬が多かったり、出走頭数が少ないと大きくなりがちになるので、単なる数値の大小では予測しにくい。 2. 予測数値に開きがあれば、その馬が対象レースにおいてはかなり強いであろうことが予想される。 だからです。
以下、この条件で検証した結果です。
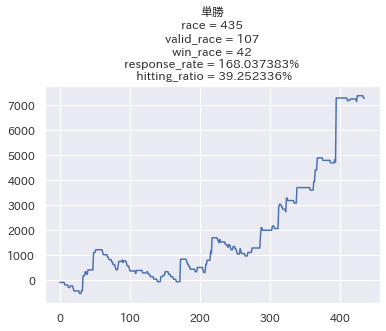
😆めちゃくちゃ良い感じじゃん😆
的中率は26%→39%に、回収率は130%→168%へと大幅に改善されました。
対象レースはさらに250レース程減って年間100レースに絞られましたが、それでも1/4は参加していると考えると、この回収率は良いと思います。
他の馬券も一応みてみます。




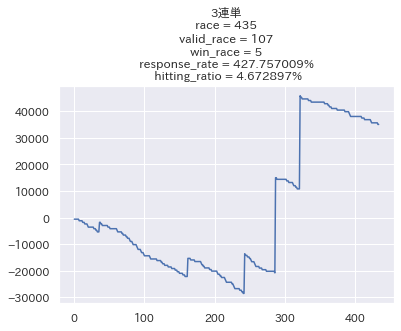
良いですね! 特筆すべきなのは複勝の的中率が70%を超え、回収率も100%を超えている点です。 1番人気の馬の複勝圏内率は約60~65%程度(参考:開発者ブログ | 株式会社AlphaImpact)らしいので、これは非常に良いと言えます。
特徴量について
モデルを作ったときの特徴量の重要度についてもみていくことにします。
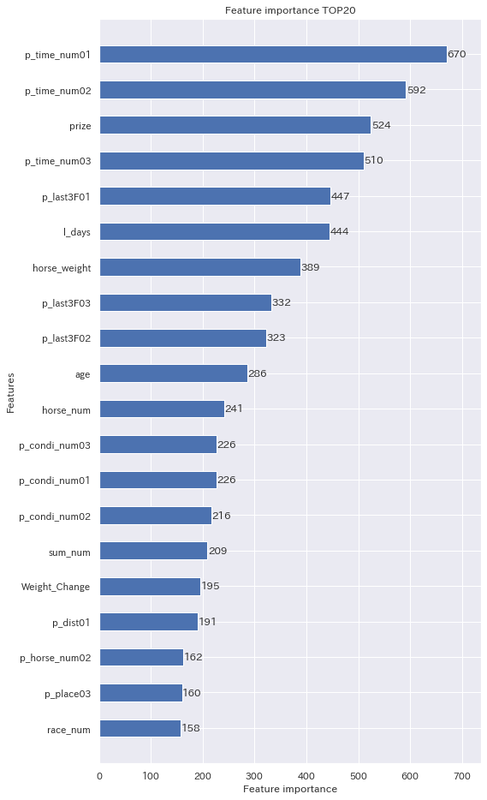
タイム指数がかなり重要な特徴量として扱われているのが分かります。当たり前ですが、過去のレースで良い走りをした馬が勝つ確率が高いということですね。
意外だったのは、前回のレースから何日経っているかが、上がりタイムや馬体重と同じくらい重要な特徴量として扱われている点です。近年の強い馬はローテを考え、あまり使い詰めていなかったりするので、そういう部分が効いてきているのかもしれませんね。
追記
実験的に、作成したプログラムでの予想をブログで公開しています。(無料です) 果たしてちゃんと当たるのかどうかは分かりませんが、興味のある方は覗いてみてください! https://ai-umatan.hatenablog.com ただ外れても私は何の責任も負いませんので、あくまでも馬券購入は自己責任でお願いします。🙇♂️
おわりに
昨今、競馬AIはサービスとして運営しているサイトもあったり、ドワンゴが主宰の電脳賞があったり(最近はやってないけど…)と、着々と盛り上がっているように思えます。そんな中で自分も機械学習を使った競馬予想を実践することができとても楽しかったです。
ただ未来を完璧に予想することはできないので、このモデルを使ったからといって確実に勝てるかと言えば、そういうわけではありません。今年、来年のレースでは惨敗してしまうこともあり得るでしょう。
こういうものに期待しすぎるのもよくないとは思いますが、競馬プログラムで稼いでいる人もいるので、夢はあるのかなと思います。